When you make decisions about what to watch as you open YouTube in your lunch break or Netflix in the evening, what to buy from Amazon or eBay or what to read as you scroll through your news feed, you are guided by machine learning-based recommendation systems that are ubiquitous throughout services offered by Big Tech. Indeed, it may have been via a ML-based recommendation that you came across this article.
These models determine the similarity of videos, products or stories to other things you like and serve up recommendations.
The two most common kinds of recommendations are:
- Homepage Recommendations: Items are personalised to each user, based on their known interests.
- Related Item Recommendations: Items are rated by similarity to a particular item.
Recommendation systems help users find compelling content in a large corpus (i.e. millions of items on Amazon, or billions of videos on Youtube), outside of what they may wish to search for, and the algorithms behind them are becoming more effective all the time.
Google has said that 40% of app installs on Google Play and 60% of watch time on Youtube comes from recommendations!
However, in addition to serving our every whim like an omniscient butler, recommendation models can be adapted and retargeted for other uses which may provide new insight and opportunities. In this project, I’ve adapted Google’s Recommendation Systems with TensorFlow notebook, which uses matrix factorization to learn user and movie embeddings, to instead learn location and plant species embeddings.
Trained using the Atlas of Living Australia (ALA) dataset, containing 70,000 plant species observations and locations, this model allows for personalised species recommendations for users (like a homepage recommendation) and related species recommendations (which brings up a list of plants that may grow in similar conditions).
Content-Based vs Collaborative Filtering
There are two common approaches to generating a set of relevant candidates:
| Type | Definition | Example |
|---|---|---|
| content-based filtering | Uses similarity between items to recommend items similar to what the user likes. | If user A watches two cute cat videos, then the system can recommend cute animal videos to that user. |
| collaborative filtering | Uses similarities between queries and items simultaneously to provide recommendations. | If user A is similar to user B, and user B likes video 1, then the system can recommend video 1 to user A (even if user A hasn’t seen any videos similar to video 1). |
Since content-based filtering requires a lot of domain knowledge, i.e. data on preferred climate or soil pH, which the ALA dataset does not contain, this project uses a collaborative filtering approach, with the following benefits:
- No domain knowledge necessary – the relations between items are automatically learned
- Serendipity – this model can help users discover new interests, or in this instance, new plant combinations previously not considered by botanists or gardeners. In isolation, the ML system may not know the location would suit a given species, but the model might still recommend it because the species is already found in similar locations.
Google Colab Notebook
The Google Colab Notebook can be found here, which you can run from your browser and generate your own recommendations.
Exploring the Atlas of Living Australia (ALA) dataset
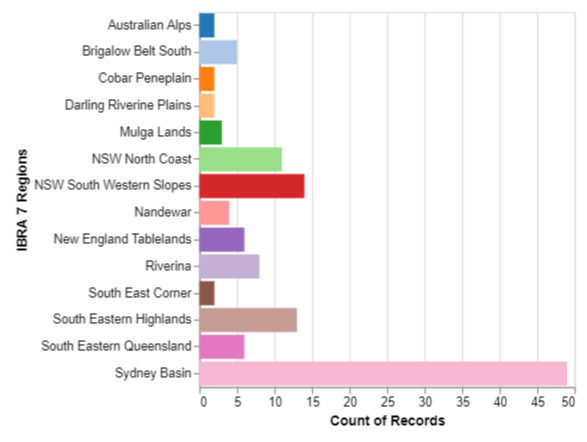
Before we dive into exploring the findings, lets inspect the ALA dataset. The dataset (plantsdb1.zip) contains 69,049 plant observations, which is split into 3 dataframes containing locations (NSW local government areas), unique plant species and observation records.
There are records from 127 Local Government Areas, with many of these from the Sydney Basin region.
The species with the highest record count is Grevillea Juniperina - a very common sight in gardens and suburban areas in NSW.
| Plant ID | Scientific Name | Record Count |
|---|---|---|
| 1567 | Grevillea juniperina subsp. juniperina | 2113 |
| 2585 | Ranunculus anemoneus | 1562 |
| 189 | Alternanthera denticulata | 1516 |
| 2134 | Niemeyera whitei | 1411 |
| 1032 | Dillwynia tenuifolia | 1194 |

Training a Matrix Factorization Model
In order to begin building our plants recommendation system, we need to build a machine learning model and train it. This model uses a Matrix Factorization Model, popularized by the winner of the Netflix prize challenge in 2006. You can explore in the Google Colab Notebook how this model is trained and regularized.
Inspect the results
User Recommendations
The Plant Recommendation System enables users to rate plant species in the same way you might rate a show you recently watched on Netflix, and then generate recommendations. This could be useful for a council botanist or gardener looking to increase biodiversity in their area with species that are likely to be successful based on similarity with other regions. The ratings system enables them to give positive or negative weighting to species that are to be encouraged or avoided (like invasive weeds).
I went through the list and rated 3 plants commonly found in desert regions a five out of five (note: images are added manually):
| Mulga (Acacia Aneura) | Narrow-leafed Hop Bush (Dodonaea viscosa) | Sturt’s Desert Pea (Swainsona formosa) |
|---|---|---|
 |
 |
 |
Let’s see which plant species the model recommends. We’re using the ‘cosine’ method to calculate distance. -
user_recommendations(reg_model, COSINE, exclude_rated=True, k=5)
| plant_id | cosine score | Scientific Name | Order | |
|---|---|---|---|---|
| 2814 | 0.702 | Sida cunninghamii | Malvales |  |
| 1276 | 0.699 | Eucalyptus largiflorens | Myrtales |  |
| 1160 | 0.693 | Enteropogon acicularis | Poales |  |
Looks like the recommendations are accurate! The first three species are of different orders - there are shrub, tree and grass species - but all can thrive in red earths, sandy loam and heavy clay and can tolerate drought.
Related Plant Recommendations
The next part of this model displays nearest neighbours of any plant in the dataset. There’s potential relevance for rewilding abandoned mining sites or barren fields, lacking in biodiversity.
To test the quality of the recommendations, I’ve used the Ranunculus anemoneus or the Anemone Buttercup, a robust, perennial herb found in alpine Australia across several local government areas.

Below are the nearest neighbour recommendations based on this species. Again, despite sightings across several local government areas, the generated closest matches are plants of different types (wildflower, grass, orchid), but like the Anemone Buttercup, are at home in alpine regions.
| plant_id | cosine score | Scientific Name | Order | |
|---|---|---|---|---|
| 1049 | 0.982 | Diuris ochroma | Asparagales |  |
| 1362 | 0.981 | Euphrasia collina subsp. diversicolor | Lamiales |  |
| 2687 | 0.978 | Rytidosperma pumilum | Poales |  |
Visualising Plant Relations
Google’s Recommendations notebook which has been the basis for this project included a very cool scatterplot visualisation of the plant embeddings using Altair. The below chart is a 2D representation of the 30+ dimensions within the ML model. It is interactive and plants may be selected by order.
You should be able to observe the structure in the scatterplot and the clustering which indicates groups of plants that share a significant degree of similarity.
The notebook on which this work is based is Copyright 2018 Google LLC.
Licensed under the Apache License, Version 2.0 (the “License”);
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an “AS IS” BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.